Transformer
学习了李宏毅的Transformer视频,需要了解的知识:
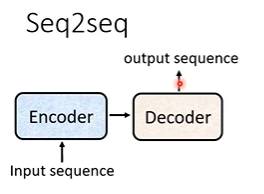
首先介绍一下Sequence-to-sequence问题(Seq2seq),输出的长度取决于模型。比如语音识别和翻译。
主要有两步,编码和解码:
Encoder操作
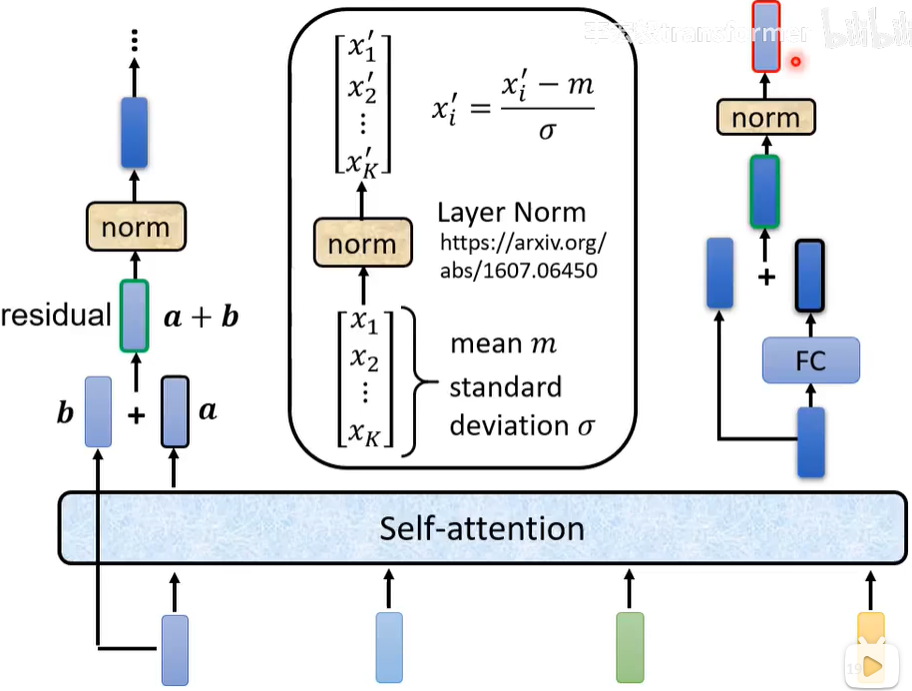
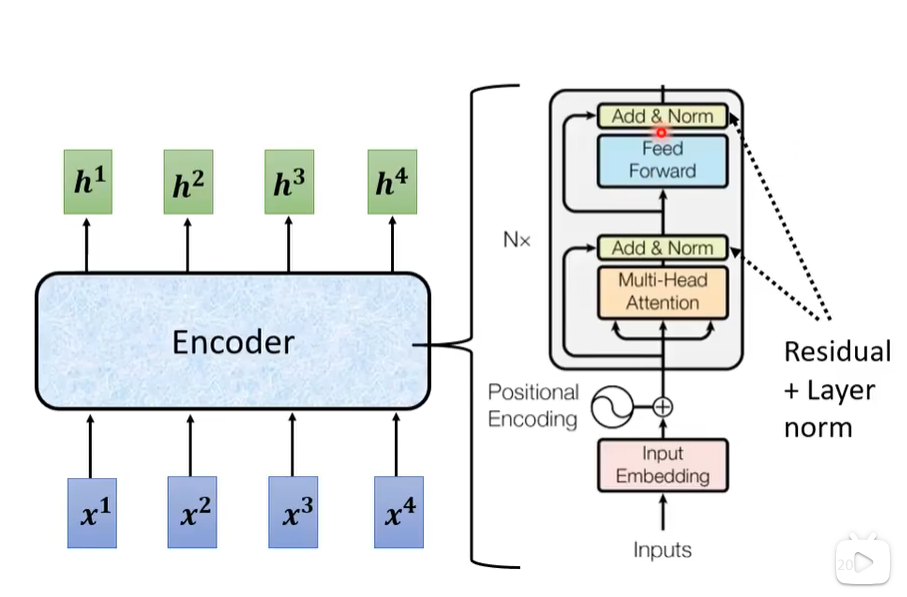
先介绍一下Encoder中常用的一些操作,如下图。首先通过自注意力机制得到的向量通常会加上自己的向量,这步操作叫做residual(剩余的),没说为什么这样设计。之后通过norm操作,即归一化(详情看图)。如果是前向神经网络(FC=Full Connected=全连接)网络也是通过residual操作并通过norm。
接下来看Transformer是如何设计Encoder的,如下图,对输入向量加入位置信息(自注意力机制中有提过),之后使用多头注意力机制,Add表示residual操作,Norm就是Norm,之后通过前向传播,再通过Add和Norm。
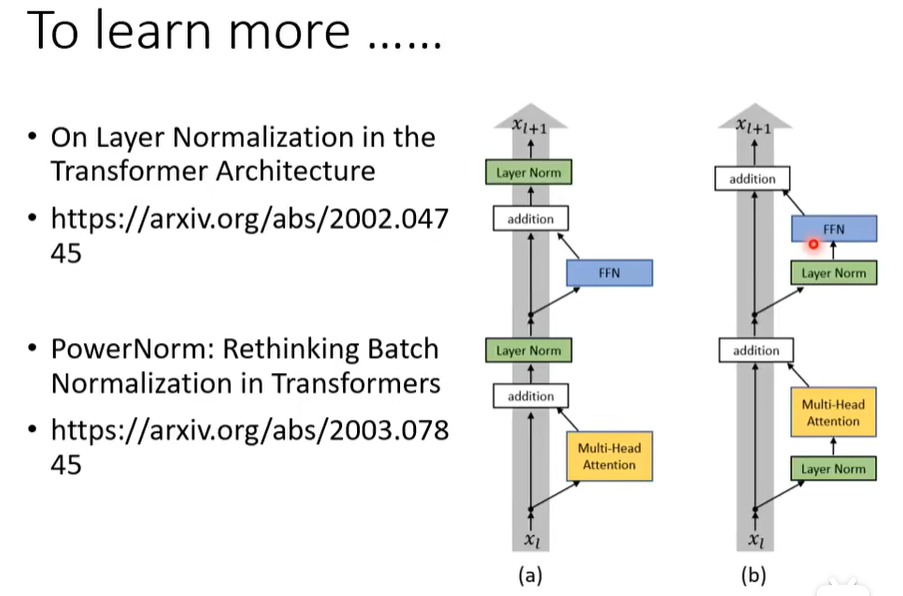
但这个顺序其实是可以更改的,如下图。区别在于(b)是每次都先Norm在进行操作,之后加上原值。
Decoder操作
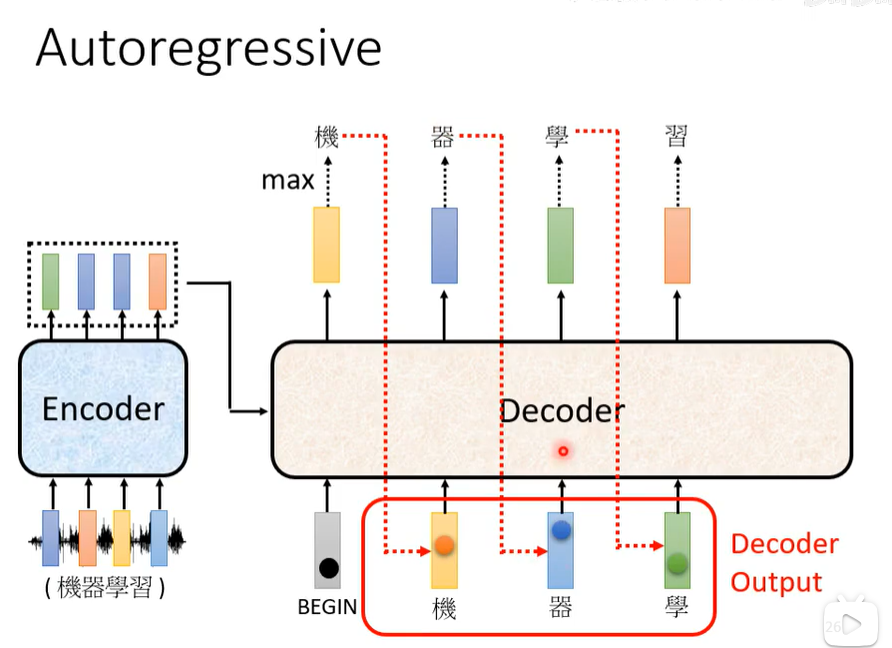
Decoder的流程如下图(autoregressive),第一次输出Begin,之后每次输出一个字,并将输出的字作为输出放进下一次输入。
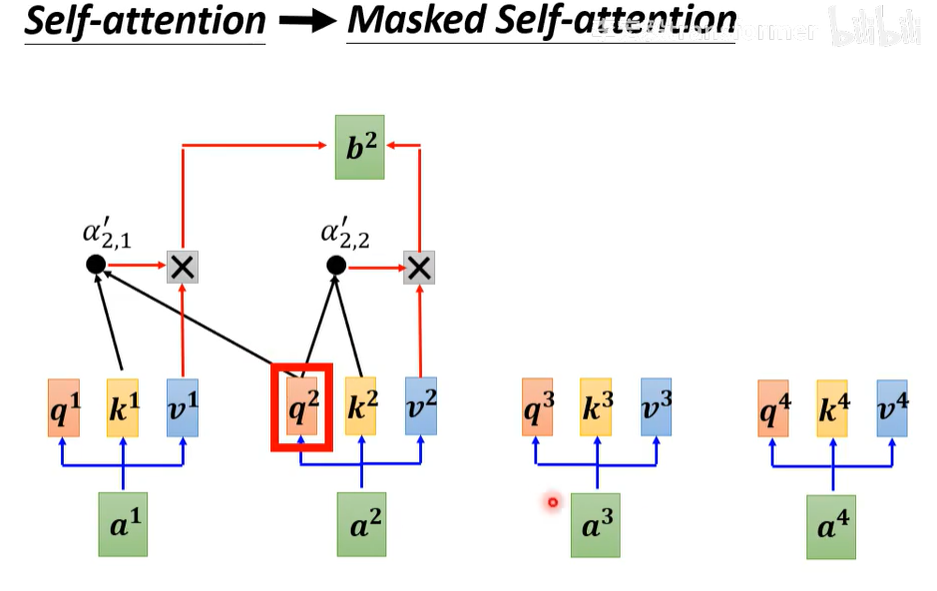
Masked Self-attention与Self-attention的区别在于一个是同时输入所有向量,一个是只能看到当前向量前面的向量。这是因为在Decoder中字是一个一个产生的,他只能考虑左边的东西。
那如果让Decoder按照上面的流程一个字一个字的输出,该如何终止?因此需要设置一个终止标记,当达到终止标记时即句子输出完成。
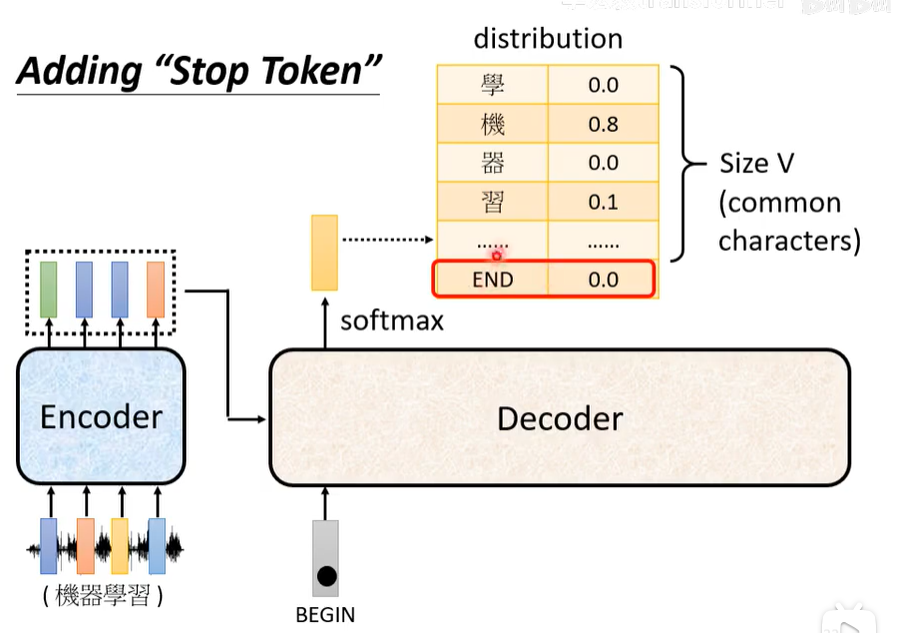
另外还有一个中止的方法,上面的这个输出一个字并把它作为输入迭代进入Decoder直到终止标记的方法叫做AT。另外下图右边这种放入多个Begin并输出的方式叫做Non-autoregressive(NAT),end右边可以不用看了。但是需要另外的方法去确定句子长度(预测或人为给定)。
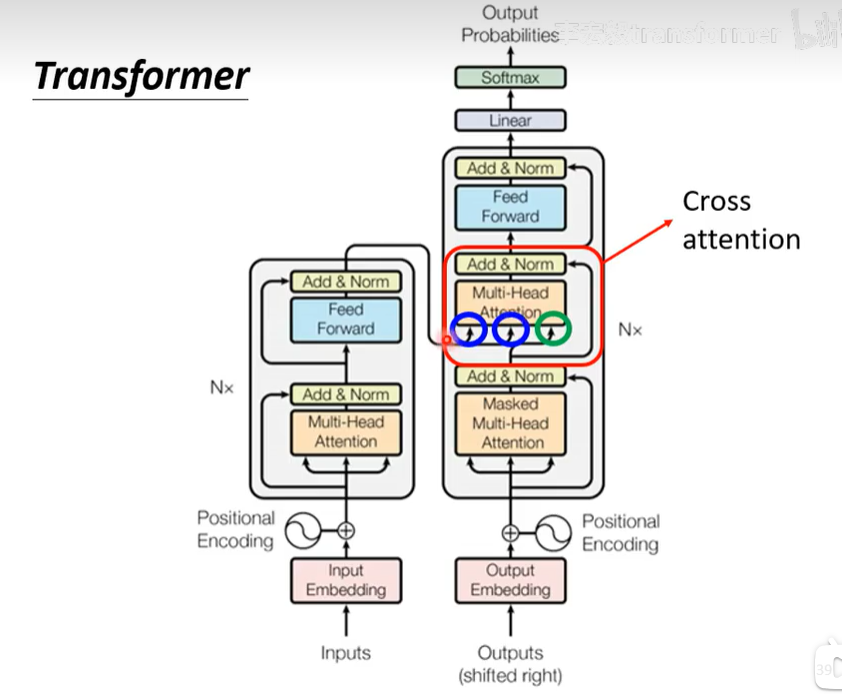
Transformer的运作机制(cross attention)
如下图所示,其中两个箭头来自encoder,一个箭头来自masked多头注意力。
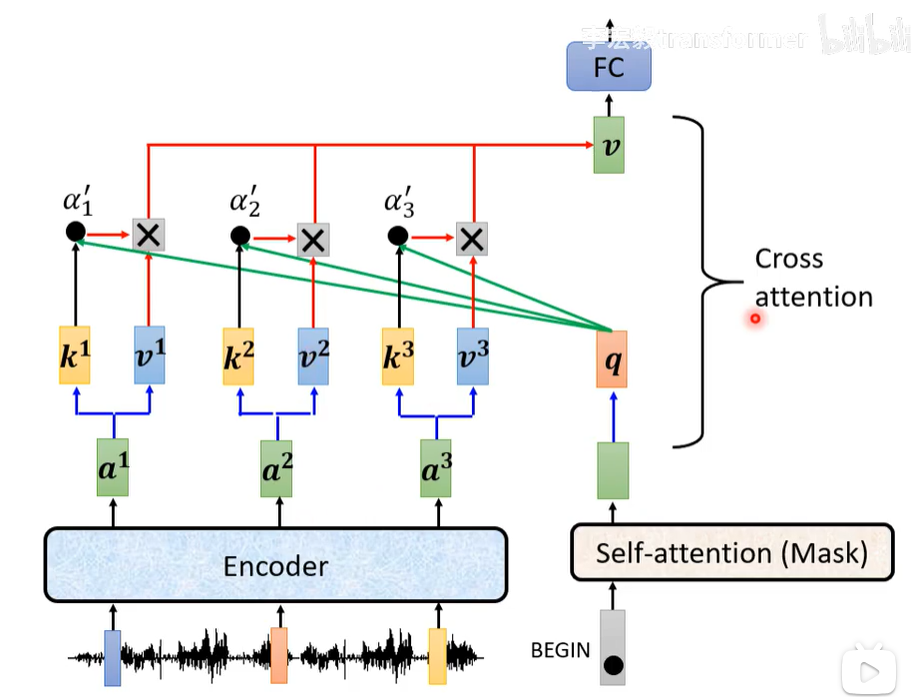
如下图所示,左边是Encoder得到的向量,计算它们的kv值,右边是输出的一个单词计算他的q值,通过他们的qkv值来计算输出并输入FC(全连接网络)。
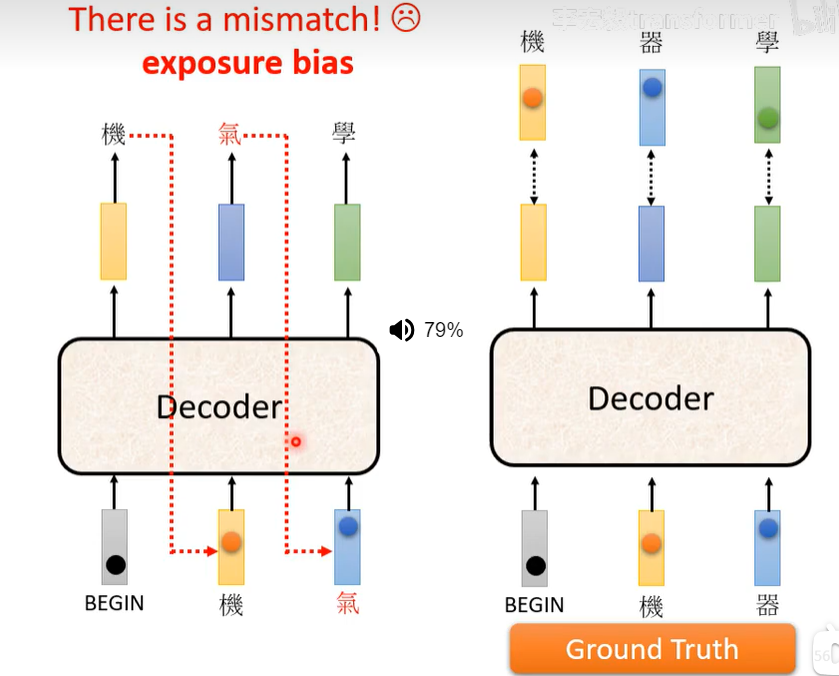
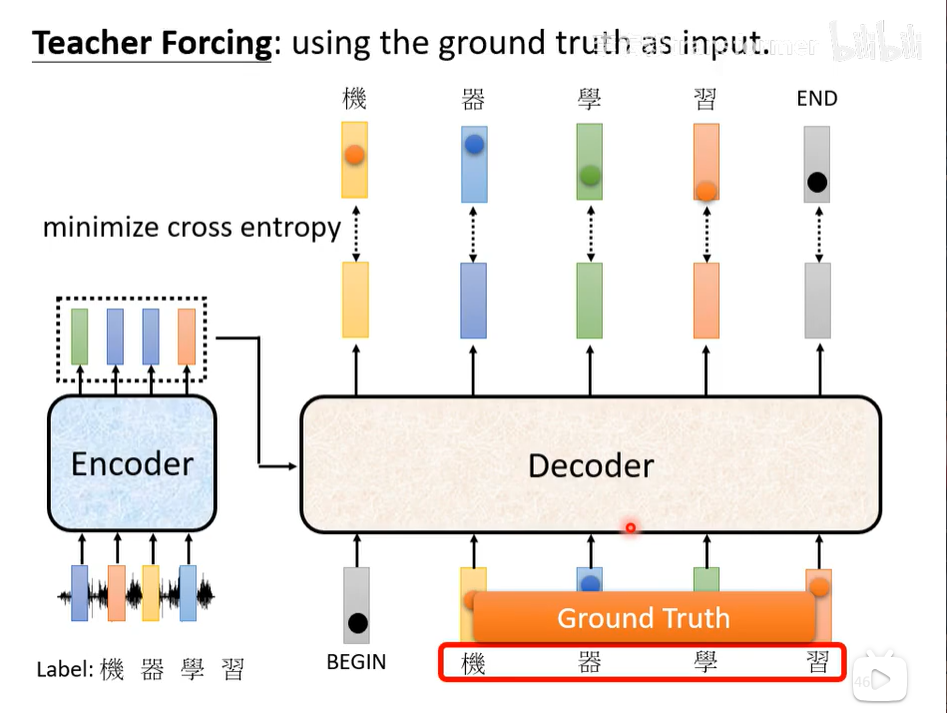
值得注意的是在训练的时候输入的全是每个单词的正确答案,这叫做teacher forcing,另外为了提高准确度,我们会给定错误的单词训练(google员工说的,实际上确实)。
其他的知识
复制模型:pointer network
例如:
- 你好,我叫库洛洛
- 库洛洛你好,我有什么可以帮到你。
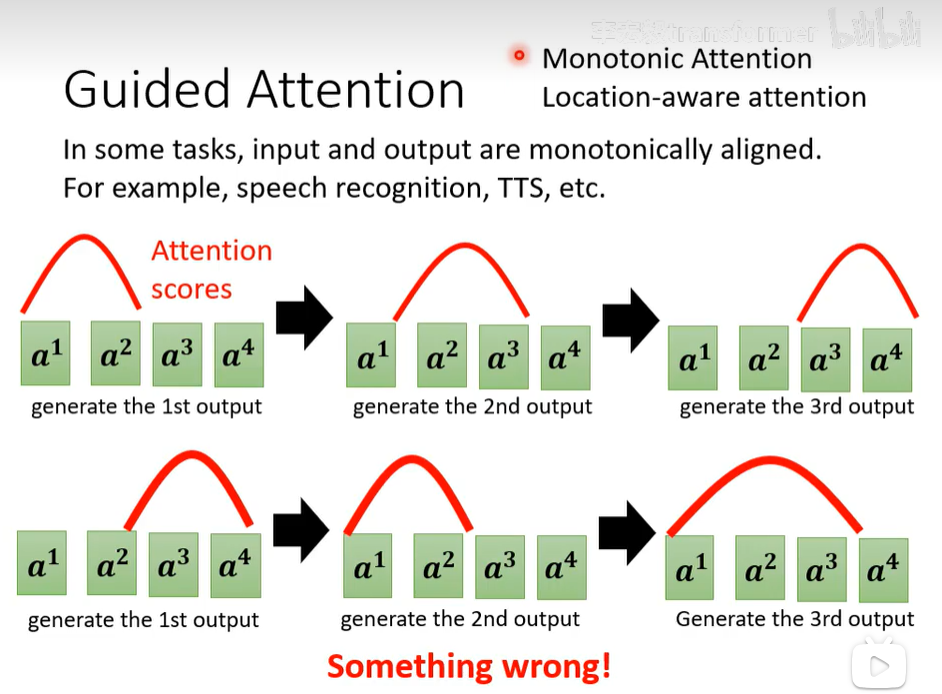
指导注意力
发现attention的得分颠三倒四的,应该你希望后面的基于前面一个生成,但attention得分却非常的乱,因此你可以使用monotonic attention,location-aware attention
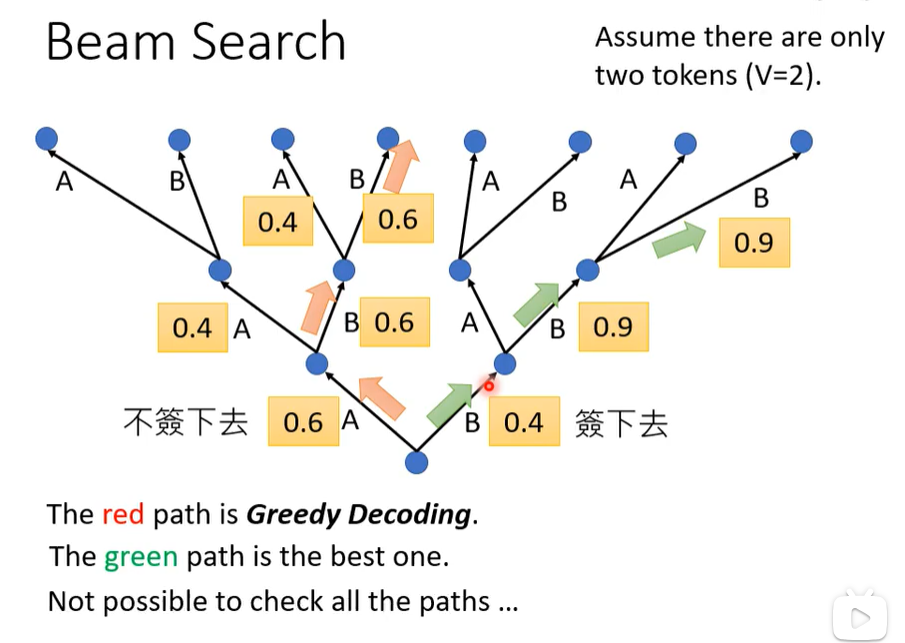
beam search
贪心不一定最好,取决于任务。
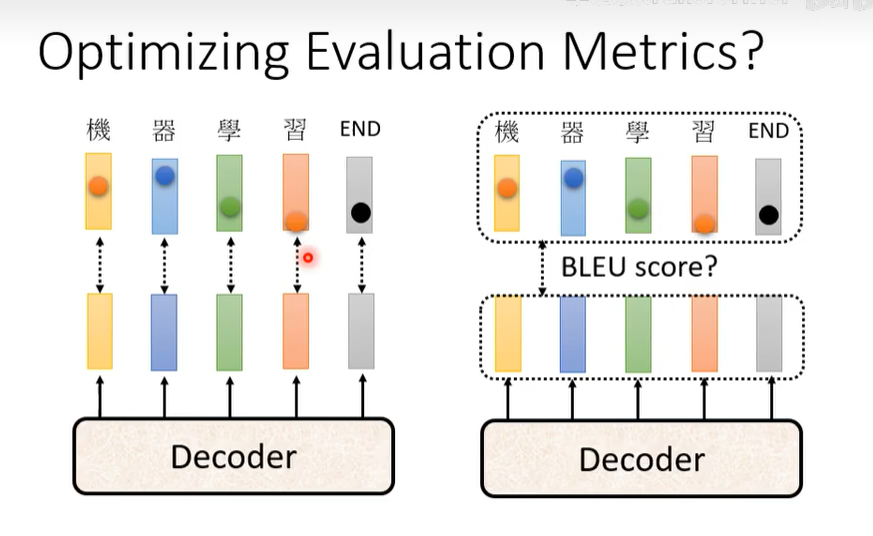
optimizing evaluation metrics
训练的时候是每个单词作比较,而最后bleu score是整个句子作比较,因此可以直接把bleu score去训练。
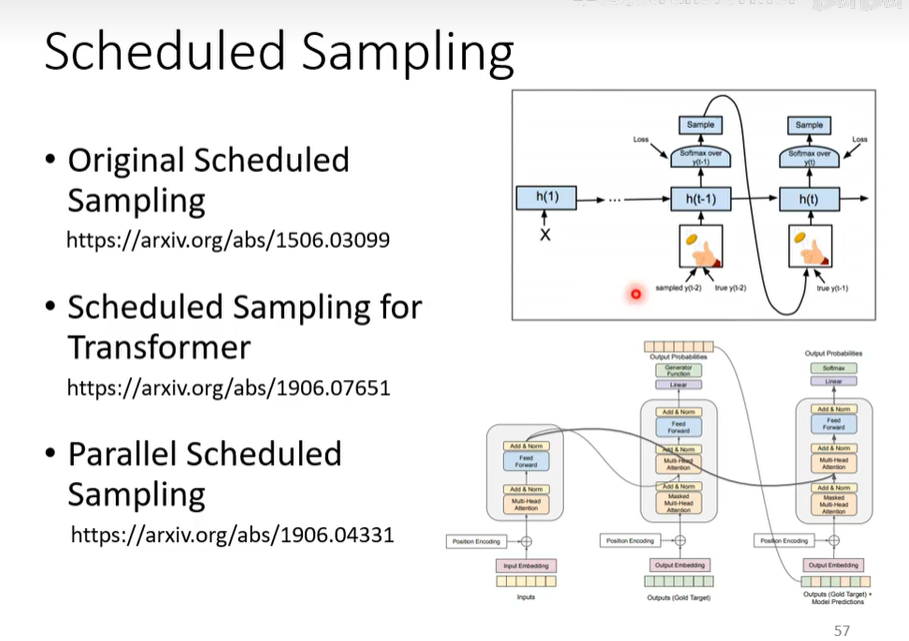
Scheduled Sampling
就是给一些错误的数据去训练提高鲁棒性。